模式识别大作业-狗脸识别
1. 题目要求
(1)PCA狗脸识别
采用PCA狗脸识别的方法完成下面的实验。图像特征可以采用灰度像素值、颜色直方图等。
1.用每个品种的一半数据做训练,另一半数据做测试(可以前40张图像作为训练,后40张图像作为测试)。采用K近邻分类(必做:K=1,选做:K=3,5),分析选取不同的主分量个数,对识别率和虚警率的影响。
2.评价该方法的性能
3.计算每个品种的正确识别率
4.进行开集测试(见题目要求3)
(2)Fisher狗脸识别
采用线性判别准则的方法进行实验。
1.用每个品种的一半数据做训练,另一半数据做测试(可以前40张图像作为训练,后40张图像作为测试)。给出用fisherface方法得到的识别率。
2.同PCA一样,评价该方法的性能
3.进行开集测试(见题目要求3)
4.比较这两个方法的优缺点
(3)开集测试
图像数据中还有80张负样本(neg,猫脸),即非狗脸图像。此时需要给出一个合理的拒识方式来判断 某张图像是否属于训练的10个品种。请设计一个合理的拒识方式(最简单的方式是对测试图像到训练 图像的最近距离设定一个阈值)并对400张狗脸测试图像和80张猫脸测试图像进行识别(11个类别,最后一个为neg类),观察阈值不同时对识别结果的影响。
(4)选作部分
1.(选做)根据上面的评价比较,给出改善,并且对新方法再进行评价
2.可以采用更加复杂的特征如HOG,BOW特征,也可以在分类方法上采用别的方式(如SVM、层级式分类)而不是K邻分类。鼓励同学们创新。
3.需要有曲线,表格和测试数据的说明
2.实验内容
实验总体介绍:本次实验我共尝试使用了三种不同的图像特征进行比较:(1)灰度像素值; (2)LBP特征; (3)HOG特征。每一种图像特征又结合下面四种算法:(1)PCA; (2)Fisher; (3)SVM; (4)HOSVD 来进行分类,并且采用了开集测试和10折交叉验证的方式分析算法的正确率。下面是实验的分析过程和分析结果
2.1 特征选择和提取
下图显示了要识别的10个品种的狗,每个品种的狗只选择了其中一张图像,下文中提到的狗的品种编号按照下图中从左到右从上到下的方式进行索引。

下图显示了实验使用的三种特征,从左到右分别是原图(第一条狗的第71张图像)以及它对应的灰度图、LBP特征图、HOG特征图,得到的数据分别存储在数据结构gray,lbp和hog中,然后保存为mat格式的文件,因为数据量比较大,每次重新提取会耗费大量时间,所以采用先保存在需要的时候再进行加载的方式。对于一张大小为144x144的图像,灰度像素特征共有144x144个;LBP特征采用的半径是1,取8个领域,所以特征共有142x142个;HOG特征采用的cell的大小为9,所以特征共有9x9=81个。

2.2 特征值和特征脸的观察
下图显示了对所有灰度图像的特征值进行分析得到的结果,左图显示了各个特征值在总特征值之和中所占的比例,很明显只有前面几个特征值具有较高的比例,后面的特征基本上都是冗余的;右图显示了特征值的累计之和在总特征值之和中所占的比例,通过观察也不难发现前面一些特征的累加便可达到90%以上的比例。
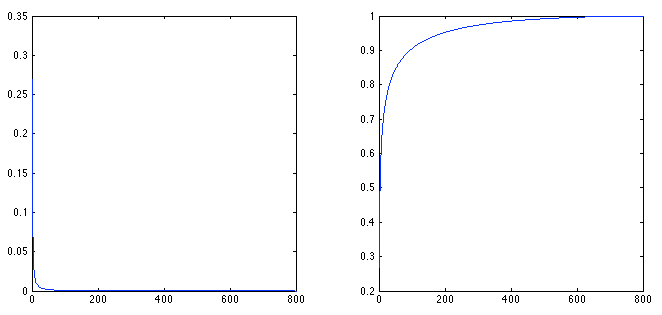
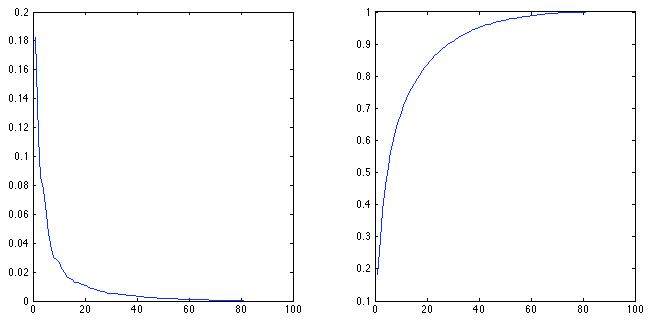
假设保证使用90%作为选择主成分数目的阈值标准,那么对于灰度像素特征,通过计算得到共需要前95个特征。对于LBP特征和HOG特征同样可以进行上面的分析,下面是HOG特征的结果,因为总共只有81个特征,所以计算很快,但是要达到90%以上的比例需要29个特征。另外,LBP特征因为它的特殊性,它需要649个特征才能达到90%以上的比例。
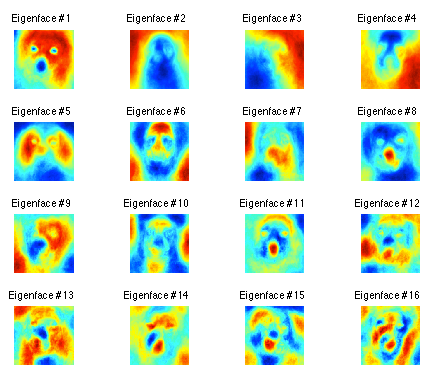
下图显示了灰度特征下得到的狗的前16个特征脸,为了增强可视性,我使用了方法colormap(jet(256))提高显示效果。从结果中可以看出,第一个特征脸就很像一只小狗,其他的特征脸因为抓住的是狗脸的其他特征所以只是隐隐约约可见狗脸的轮廓。
同样的,也可以查看下LBP特征下的特征脸,下面是前16个特征脸的显示结果,从结果中可以看出,LBP很好地抓住了狗脸部眼睛和鼻子的特征。

2.3 性能测试方式选择
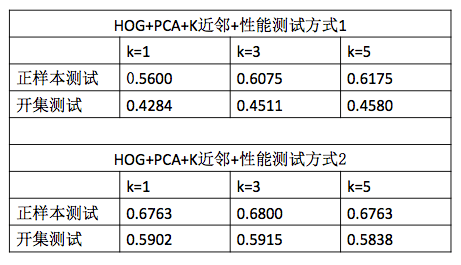
本次实验尝试了两种性能评价方法,一种是题目要求的取前40张图像作为训练,取后40张图像作为测试;另一种是常用的10折交叉验证的方法,每次从每个品种中选择8张(80/10=8)图像作为测试,其他的72张图像作为训练。例如,对于HOG特征,采用PCA和K近邻算法结合的狗脸识别得到的结果如下,可以看出一般开集测试的准确率都低于它对应的正样本测试得到的准确率,此外,采用交叉验证得到的准确率也要略高于第一种性能测试方式。另外,从理论上来说,交叉验证的性能评价方式更加科学,结果准确性更高,所以后面的结果大部分都采用交叉验证的性能测试方式,只是对于SVM和HOSVD这类复杂的运行时间长的算法采用第一种性能测试方式。
2.4 开集测试的阈值选择
上面的结果使用的阈值是负样本中的采用欧式距离度量情况下得到的最大距离M和最小距离m的平均值(M+m)/2,实验过程中我只尝试了两种不同的阈值比较,一个是使用最大距离M(使用最小距离m的话效果非常差,不作为比较之中);另一种便是使用均值(M+m)/2。下面是使用HOG特征在PCA和最近邻算法下得到的结果,左图是使用均值的情况,右图是使用最大距离的情况。两者的准确率分别是58.09%和62.05%,最大距离稍微高些,但是仔细观察最后一行和最后一列,对于使用均值距离容易出现很多狗被认为不是狗,对于最大距离容易出现很多猫被认为是狗!相比较而言,我认为后者的风险更大,所以我采用的阈值是均值。
2.5 PCA狗脸识别
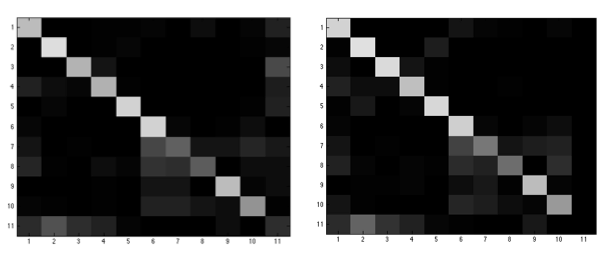
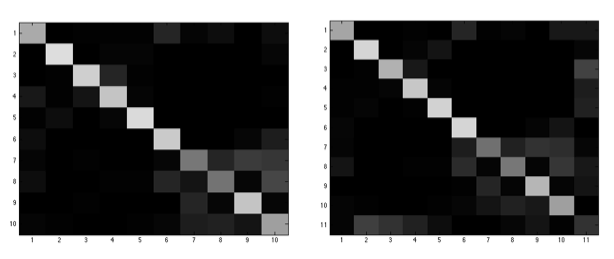
如果使用PCA以及K近邻算法进行狗脸识别,采用10折交叉验证方法对测试算法性能,对于不同的图像特征和K的取值得到下面的结果。从结果中可以看出,HOG特征的结果最优(平均都在60%以上),其次是灰度像素特征(稳定在50%左右),表现最差的是LBP特征(不超过30%);在运行速度方面,HOG特征的运行速度最快,灰度像素特征和LBP特征的运行速度都比较慢。此外,对于不同的k近邻,HOG特征的结果差别不大,相当稳定;灰度像素特征受影响比较大,因为样本中图像的灰度差别比较大,同一个品种的狗的图像的灰度差别也比较大,甚至有些品种的狗本身就存在多种肤色的情况。[结果A/B分别表示对应的正样本测试和开集测试下的准确率,下同]
下图是对于灰度像素特征得到的性能图,左边是正样本测试的结果,右边是开集测试的结果。从图中可以看出,判断错误的情况还是比较多的,尤其是比较多的错判为2和5两个品种的狗,这两个品种的狗都是褐色的,在狗的颜色当中比较具有代表性。
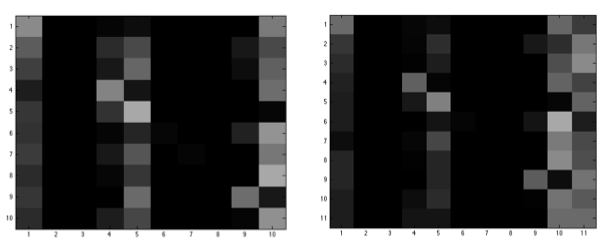
下图是对于LBP特征得到的性能图,左边是正样本测试的结果,右边是开集测试的结果。从图中可以看出,很多狗都被错误地判断为1、5和10三个品种的狗,观察发现这三种狗的脸部形状、眼睛和鼻子的分布在狗当中比较具有代表性。
下图是对于HOG特征得到的性能图,左边是正样本测试的结果,右边是开集测试的结果。从图中可以看出,后面4个品种的狗的脸部相似性比较高,观察发现这四种狗的毛发比较多,因为导致它们的HOG特征相似性比其他品种的狗要高一些。
下图是HOG特征在k=1的情况得到的各个品种的狗的识别准确率 [准确率比较容易得到,下面就不显示该类结果了]

2.6 Fisher狗脸识别
如果使用LDA以及K近邻算法进行狗脸识别,采用10折交叉验证方法对测试算法性能,对于不同的图像特征和K的取值得到下面的结果。HOG特征只有81个,数目小于N-C=((720-80)-10)=630,所以不能使用。从结果中可以看出,使用Fisher识别算法采用LBP特征比灰度像素特征更好些,在运行速度方面,两者的的运行速度差不多,但都比较慢。此外,对于不同的k近邻,灰度像素特征此时受影响程度不大,LBP特征受影响程度也不大。
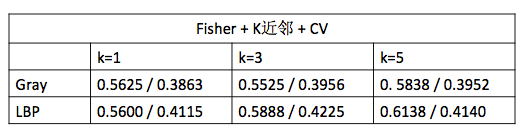
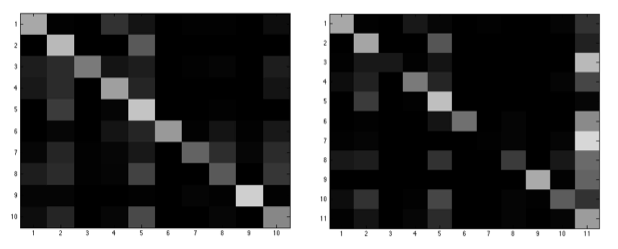
下图是对于灰度像素特征得到的性能图,左边是正样本测试的结果,右边是开集测试的结果。从图中可以看出,判断错误的情况基本上都是错判为品种5的狗,原因可能是品种5的狗在狗中是最为常见最为标准的样子。
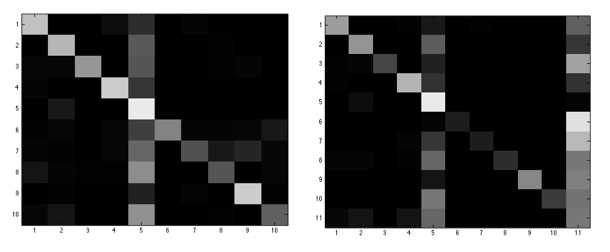
下图是对于LBP特征得到的性能图,左边是正样本测试的结果,右边是开集测试的结果。从图中可以看出,LBP特征在Fisher识别中的效果比PCA识别中的效果好很多,而且,通过右图可知拒识率相当高,也就是说虽然使用Fisher识别比PCA识别准确率高了不少,但是虚警率同样高了很多。
下图是灰度像素特征下得到的Fisher脸,下图的结果不容易看出的结果,部分图像隐约可见某个品种的狗脸轮廓,其中包括了狗的眼睛和鼻子。

与PCA狗脸识别对比:PCA识别的优点是速度快,Fisher略微慢些;在PCA中LBP特征准确率非常差,但是在Fisher中LBP特征的结果相当不错,超过了灰度像素特征;对于灰度像素特征,Fisher识别的准确率要比PCA识别的准确率要高,但两者将狗识别为非狗的情况都特别多;运行时间方面,两者的运行时间差不多。
2.7 SVM算法狗脸识别
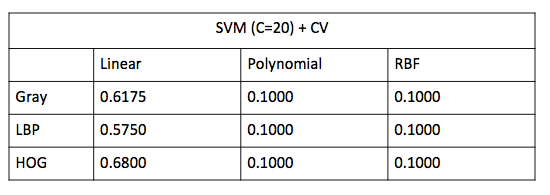
实验的过程中我分别测试了线性(linear)、多项式(polynomial)和径向基(RBF)三种不同核函数的SVM算法,经过测试之后我将参数C统一设置为20,以下是不同特征和核函数得到的结果。此外,因为SVM算法的训练需要比较长的时间,所以这里就不采用交叉验证的方式,而是采用第一种性能测试方式(一半训练另一半测试)。很明显,不同情况下的结果差别很大,例如,对于HOG特征,在线性SVM中得到的结果最好,接近90%,但是对于多项式和径向基核函数只能得到10%的准确率,这也说明了线性SVM虽然是最简单的SVM,但是在特定情况下没准是性能最好的SVM。 [尚不清楚三种特征在多项式核函数和径向基核函数的情况下都是10%的原因,不排除是不合适的参数造成]
2.8 HOSVD算法狗脸识别
为了做进一步扩展,我选择了HOSVD算法,即高维奇异值分解算法来和其他算法的性能进行对比。HOSVD算法是SVD算法在高维空间的扩展,在人脸识别领域使用的也比较多,相关知识参考书籍《Matrix Methods in Data Mining and Pattern Recognition》。
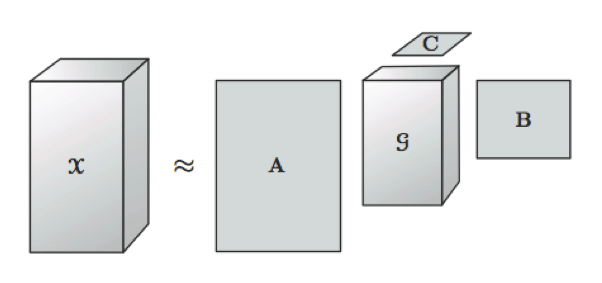
PCA算法虽然实现上比较简单,但是在不同的环境(例如光照条件)和不同的人物表情下识别率比较低,所以后来就演变出了“张量脸”算法,即HOSVD算法,它基于下图所示的张量的Tuker分解。简言之,就是将狗脸图像的某种特征视为一个列向量,将同一个品种的狗的不同图像(视为狗的不同的表情)对应的列向量组合成一个矩阵,然后将不同品种的狗对应的矩阵组合成如下图所示的张量x。HOSVD算法就是对张量x进行分解,得到一个核心张量和几个其他正交阵,更加详细的讲解参考上面书籍。
与PCA类似,它也需要给定一个主成分的参数,如果张量的维数太大的话计算机训练一个HOSVD的模型需要比较长的时间,所以,为了保证HOSVD算法能够在一定的时间内给出结果,它的输入图像不是原始的大小,而是缩小为72x72,在这样的情况下完成灰度像素特征下的HOSVD分解大概需要8分钟。考虑到运行时间过长,所以此时也改用第一种性能测试方式(一半训练另一半测试)。下面是不同的特征和k值得到的HOSVD算法的结果 [画线处表示结果未计算,可以看出其结果并不是最优的]

3 实验总结
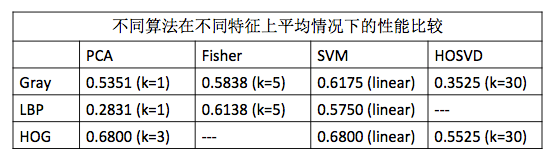
本实验从特征的选择和提取开始,一步步经过特征值的分析以及对于性能评估方法和开集测试的阈值的选择,然后依次使用PCA识别、Fisher识别、SVM算法和HOSVD算法进行识别,分析算法的结果及其性能。通过对比各种算法的平均情况下的最好的结果,得到如下结果。从对比中可以看出,平均情况下表现最好的是SVM算法,而且是在HOG特征以及线性核函数的情况下表现最优;对于PCA识别,采用HOG特征最佳;对于Fisher识别,采用LBP特征最佳;而HOSVD算法需要的时间比SVM算法还多,但是性能并没有进一步提升,所以并不是该类问题的很好解决方案。
实验评价:
(1)本实验的最大亮点在于很好地对多个特征在多个不同算法上的结果进行分析和比较,而且大胆尝试了SVM算法和HOSVD算法,但是由于对这两个略微复杂的算法的理解能力不足,没能更好地解释得到的实验结果(例如多项式和径向基核函数会得到很低的准确率的原因),也没能进一步通过调整参数使得这两个算法的性能进一步提升;
(2)实验过程中有效地结合使用两种性能测试方式缩短了实验时间(SVM和HOSVD算法使用一半训练另一半测试的方式),但是在对算法的性能进行比较的时候没能详细地比较具体的运行时间;
(3)实验过程中的分析还算是比较清晰,按照一定的逻辑不断调整策略,但是在一些阈值的选择(例如开集测试的距离阈值)、参数的选择(SVM算法的核函数的参数)方面感觉没有方向性,不能按照一定的思路朝着更好的结果进行。另外,由于缺乏数字图像处理的能力,没能对图像进行一些预处理操作,例如截取狗脸的核心区域不但可以减少特征数目,而且肯定能够提高算法的准确率。
参考资料:
1.Pattern Recognition. Sergios Theodoridis
2.Introduction to Pattern Recognition: A Matlab Approach. Sergios Theodoridis
3.Matrix Methods in Data Mining and Pattern Recognition. Lars Eldén
4.Blog of Bytefish: http://bytefish.de/blog