Python算法设计篇(8) Chapter 8 Tangled Dependencies and Memoization
Twice, adv. Once too often.
—— Ambrose Bierce, The Devil’s Dictionary
本节主要结合一些经典的动规问题介绍动态规划的备忘录法和迭代法这两种实现方式,并对这两种方式进行对比
[这篇文章实际写作时间在这个系列文章之前,所以写作风格可能略有不同,嘿嘿]
大家都知道,动态规划算法一般都有下面两种实现方式,前者我称为递归版本,后者称为迭代版本,根据前面的知识可知,这两个版本是可以相互转换的
1.直接自顶向下实现递归式,并将中间结果保存,这叫备忘录法;
2.按照递归式自底向上地迭代,将结果保存在某个数据结构中求解。
编程有一个原则DRY=Don’t Repeat Yourself,就是说你的代码不要重复来重复去的,这个原则同样可以用于理解动态规划,动态规划除了满足最优子结构,它还存在子问题重叠的性质,我们不能重复地去解决这些子问题,所以我们将子问题的解保存起来,类似缓存机制,之后遇到这个子问题时直接取出子问题的解。
举个简单的例子,斐波那契数列中的元素的计算,很简单,我们写下如下的代码:
def fib(i):
if i<2: return 1
return fib(i-1)+fib(i-2)
好,来测试下,运行fib(10)得到结果69,不错,速度也还行,换个大的数字,试试100,这时你会发现,这个程序执行不出结果了,为什么?递归太深了!要计算的子问题太多了!
所以,我们需要改进下,我们保存每次计算出来的子问题的解,用什么保存呢?用Python中的dict!那怎么实现保存子问题的解呢?用Python中的装饰器!
修改刚才的程序,得到如下代码,定义一个函数memo返回我们需要的装饰器,这里用cache保存子问题的解,key是方法的参数,也就是数字n,值就是fib(n)返回的解。
from functools import wraps
def memo(func):
cache={}
@wraps(func)
def wrap(*args):
if args not in cache:
cache[args]=func(*args)
return cache[args]
return wrap
@memo
def fib(i):
if i<2: return 1
return fib(i-1)+fib(i-2)
重新运行下fib(100),你会发现这次很快就得到了结果573147844013817084101,这就是动态规划的威力,上面使用的是第一种带备忘录的递归实现方式。
带备忘录的递归方式的优点就是易于理解,易于实现,代码简洁干净,运行速度也不错,直接从需要求解的问题出发,而且只计算需要求解的子问题,没有多余的计算。但是,它也有自己的缺点,因为是递归形式,所以有限的栈深度是它的硬伤,有些问题难免会出现栈溢出了。
于是,迭代版本的实现方式就诞生了!
迭代实现方式有2个好处:1.运行速度快,因为没有用栈去实现,也避免了栈溢出的情况;2.迭代实现的话可以不使用dict来进行缓存,而是使用其他的特殊cache结构,例如多维数组等更为高效的数据结构。
那怎么把递归版本转变成迭代版本呢?
这就是递归实现和迭代实现的重要区别:递归实现不需要去考虑计算顺序,只要给出问题,然后自顶向下去解就行;而迭代实现需要考虑计算顺序,并且顺序很重要,算法在运行的过程中要保证当前要计算的问题中的子问题的解已经是求解好了的。
斐波那契数列的迭代版本很简单,就是按顺序来计算就行了,不解释,关键是你可以看到我们就用了3个简单变量就求解出来了,没有使用任何高级的数据结构,节省了大量的空间。
def fib_iter(n):
if n<2: return 1
a,b=1,1
while n>=2:
c=a+b
a=b
b=c
n=n-1
return c
斐波那契数列的变种经常出现在上楼梯的走法问题中,每次只能走一个台阶或者两个台阶,广义上思考的话,动态规划也就是一个连续决策问题,到底当前这一步是选择它(走一步)还是不选择它(走两步)呢?
其他问题也可以很快地变相思考发现它们其实是一样的,例如求二项式系数C(n,k),杨辉三角(求从源点到目标点有多少种走法)等等问题。
二项式系数C(n,k)表示从n个中选k个,假设我们现在处理n个中的第1个,考虑是否选择它。如果选择它的话,那么我们还需要从剩下的n-1个中选k-1个,即C(n-1,k-1);如果不选择它的话,我们需要从剩下的n-1中选k个,即C(n-1,k)。所以,C(n,k)=C(n-1,k-1)+C(n-1,k)。
结合前面的装饰器,我们很快便可以实现求二项式系数的递归实现代码,其中的memo函数完全没变,只是在函数cnk前面添加了@memo而已,就这么简单!
from functools import wraps
def memo(func):
cache={}
@wraps(func)
def wrap(*args):
if args not in cache:
cache[args]=func(*args)
return cache[args]
return wrap
@memo
def cnk(n,k):
if k==0: return 1 #the order of `if` should not change!!!
if n==0: return 0
return cnk(n-1,k)+cnk(n-1,k-1)
它的迭代版本也比较简单,这里使用了defaultdict,略高级的数据结构,和dict不同的是,当查找的key不存在对应的value时,会返回一个默认的值,这个很有用,下面的代码可以看到。
如果不了解defaultdict的话可以看下Python中的高级数据结构
from collections import defaultdict
n,k=10,7
C=defaultdict(int)
for row in range(n+1):
C[row,0]=1
for col in range(1,k+1):
C[row,col]=C[row-1,col-1]+C[row-1,col]
print(C[n,k]) #120
杨辉三角大家都熟悉,在国外这个叫Pascal Triangle,它和二项式系数特别相似,看下图,除了两边的数字之外,里面的任何一个数字都是由它上面相邻的两个元素相加得到,想想C(n,k)=C(n-1,k-1)+C(n-1,k)不也就是这个含义吗?
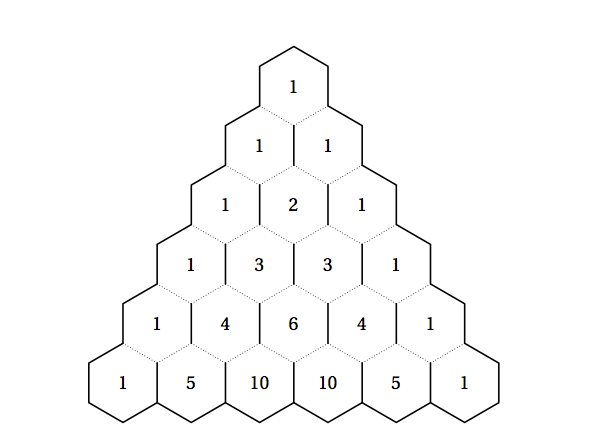
所以说,顺序对于迭代版本的动态规划实现很重要,下面举个实例,用动态规划解决有向无环图的单源最短路径问题。假设有如下图所示的图,当然,我们看到的是这个有向无环图经过了拓扑排序之后的结果,从a到f的最短路径用灰色标明了。
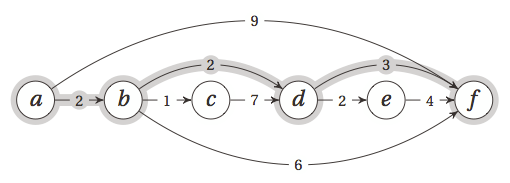
好,怎么实现呢?
我们有两种思考方式:
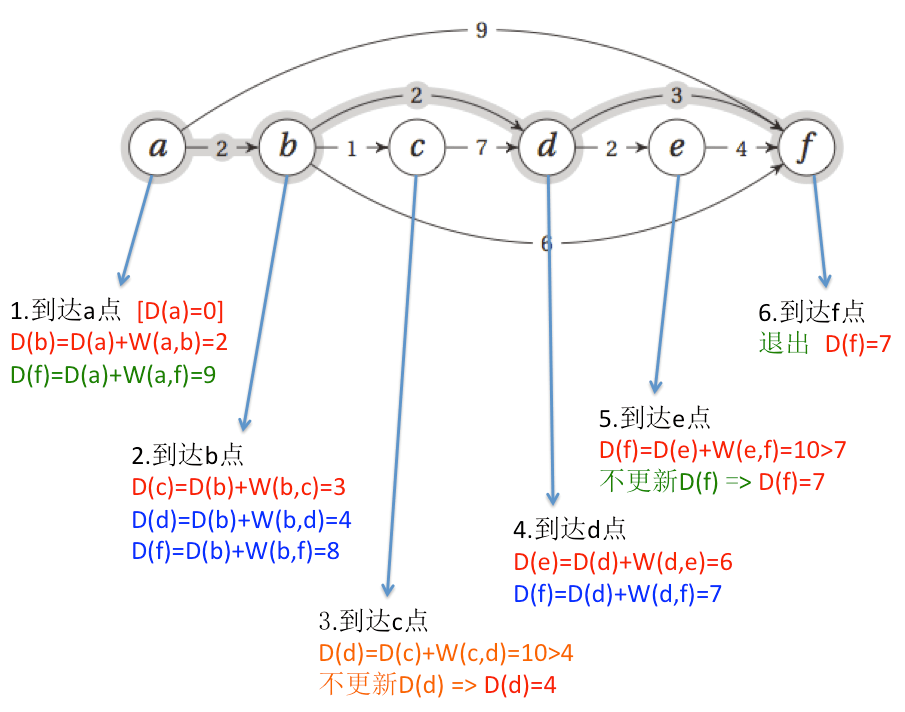
1.”去哪里?”:我们顺向思维,首先假设从a点出发到所有其他点的距离都是无穷大,然后,按照拓扑排序的顺序,从a点出发,接着更新a点能够到达的其他的点的距离,那么就是b点和f点,b点的距离变成2,f点的距离变成9。因为这个有向无环图是经过了拓扑排序的,所以按照拓扑顺序访问一遍所有的点(到了目标点就可以停止了)就能够得到a点到所有已访问到的点的最短距离,也就是说,当到达哪个点的时候,我们就找到了从a点到该点的最短距离,拓扑排序保证了后面的点不会指向前面的点,所以访问到后面的点时不可能再更新它前面的点的最短距离!(这里的更新也就是前面第4节介绍过的relaxtion)这种思维方式的代码实现就是迭代版本。
[这里涉及到了拓扑排序,前面第5节Traversal中介绍过了,这里为了方便没看前面的童鞋理解,W直接使用的是经过拓扑排序之后的结果。]
def topsort(W):
return W
def dag_sp(W, s, t):
d = {u:float('inf') for u in W} #
d[s] = 0
for u in topsort(W):
if u == t: break
for v in W[u]:
d[v] = min(d[v], d[u] + W[u][v])
return d[t]
#邻接表
W={0:{1:2,5:9},1:{2:1,3:2,5:6},2:{3:7},3:{4:2,5:3},4:{5:4},5:{}}
s,t=0,5
print(dag_sp(W,s,t)) #7
用图来表示计算过程就是下面所示:
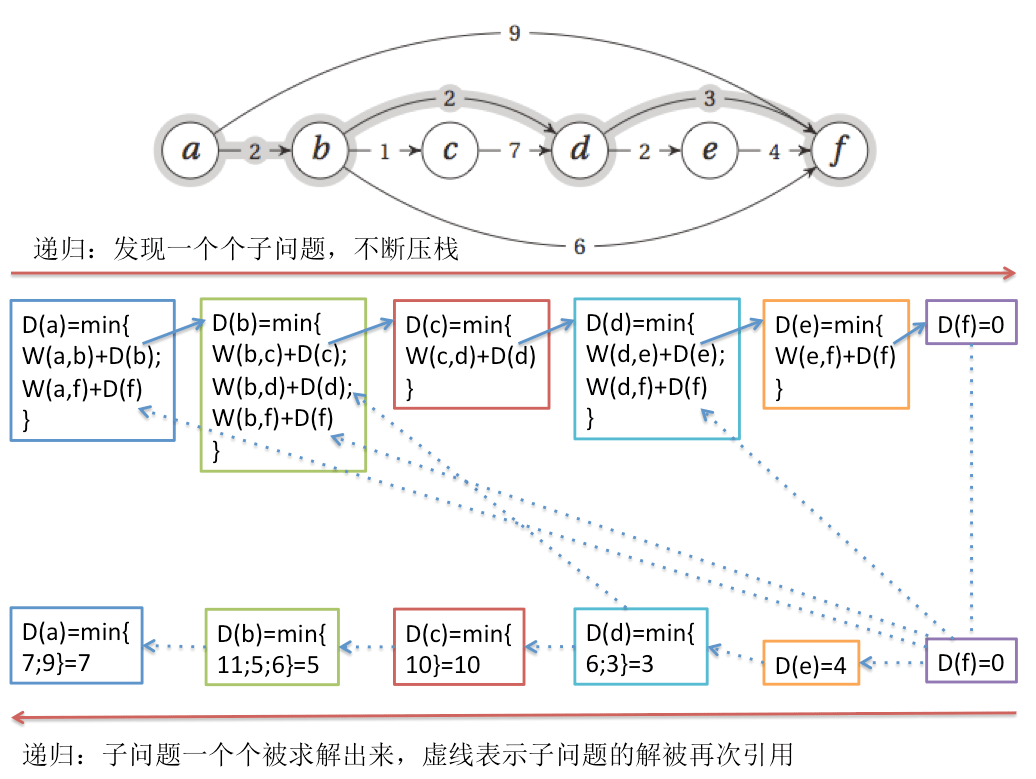
2.”从哪里来?”:我们逆向思维,目标是要到f,那从a点经过哪个点到f点会近些呢?只能是求解从a点出发能够到达的那些点哪个距离f点更近,这里a点能够到达b点和f点,f点到f点距离是0,但是a到f点的距离是9,可能不是最近的路,所以还要看b点到f点有多近,看b点到f点有多近就是求解从b点出发能够到达的那些点哪个距离f点更近,所以又绕回来了,也就是递归下去,直到我们能够回答从a点经过哪个点到f点会更近。这种思维方式的代码实现就是递归版本。
这种情况下,不需要输入是经过了拓扑排序的,所以你可以任意修改输入W中节点的顺序,结果都是一样的,而上面采用迭代实现方式必须要是拓扑排序了的,从中你就可以看出迭代版本和递归版本的区别了。
from functools import wraps
def memo(func):
cache={}
@wraps(func)
def wrap(*args):
if args not in cache:
cache[args]=func(*args)
# print('cache {0} = {1}'.format(args[0],cache[args]))
return cache[args]
return wrap
def rec_dag_sp(W, s, t):
@memo
def d(u):
if u == t: return 0
return min(W[u][v]+d(v) for v in W[u])
return d(s)
#邻接表
W={0:{1:2,5:9},1:{2:1,3:2,5:6},2:{3:7},3:{4:2,5:3},4:{5:4},5:{}}
s,t=0,5
print(rec_dag_sp(W,s,t)) #7
用图来表示计算过程就如下图所示:
[扩展内容:对DAG求单源最短路径的动态规划问题的总结,比较难理解,附上原文]
Although the basic algorithm is the same, there are many ways of finding the shortest path in a DAG, and, by extension, solving most DP problems. You could do it recursively, with memoization, or you could do it iteratively, with relaxation. For the recursion, you could start at the first node, try various “next steps,” and then recurse on the remainder, or (if you graph representation permits) you could look at the last node and try “previous steps” and recurse on the initial part. The former is usually much more natural, while the latter corresponds more closely to what happens in the iterative version.
Now, if you use the iterative version, you also have two choices: you can relax the edges out of each node (in topologically sorted order), or you can relax all edges into each node. The latter more obviously yields a correct result but requires access to nodes by following edges backward. This isn’t as far-fetched as it seems when you’re working with an implicit DAG in some nongraph problem. (For example, in the longest increasing subsequence problem, discussed later in this chapter, looking at all backward “edges” can be a useful perspective.)
Outward relaxation, called reaching, is exactly equivalent when you relax all edges. As explained, once you get to a node, all its in-edges will have been relaxed anyway. However, with reaching, you can do something that’s hard in the recursive version (or relaxing in-edges): pruning. If, for example, you’re only interested in finding all nodes that are within a distance r, you can skip any node that has distance estimate greater than r. You will still need to visit every node, but you can potentially ignore lots of edges during the relaxation. This won’t affect the asymptotic running time, though (Exercise 8-6).
Note that finding the shortest paths in a DAG is surprisingly similar to, for example, finding the longest path, or even counting the number of paths between two nodes in a DAG. The latter problem is exactly what we did with Pascal’s triangle earlier; the exact same approach would work for an arbitrary graph. These things aren’t quite as easy for general graphs, though. Finding shortest paths in a general graph is a bit harder (in fact, Chapter 9 is devoted to this topic), while finding the longest path is an unsolved problem (see Chapter 11 for more on this).
好,我们差不多搞清楚了动态规划的本质以及两种实现方式的优缺点。
OK,希望我把动态规划讲清楚了,总结下:动态规划其实就是一个连续决策的过程,每次决策我们可能有多种选择(二项式系数和0-1背包问题中我们只有两个选择,DAG图的单源最短路径中我们的选择要看点的出边或者入边,矩阵链乘问题中就是矩阵链可以分开的位置总数…),我们每次选择最好的那个作为我们的决策。所以,动态规划的时间复杂度其实和这两者有关,也就是子问题的个数以及子问题的选择个数,一般情况下动态规划算法的时间复杂度就是两者的乘积。
动态规划有两种实现方式:一种是带备忘录的递归形式,这种方式直接从原问题出发,遇到子问题就去求解子问题并存储子问题的解,下次遇到的时候直接取出来,问题求解的过程看起来就像是先自顶向下地展开问题,然后自下而上的进行决策;另一个实现方式是迭代方式,这种方式需要考虑如何给定一个子问题的求解方式,使得后面求解规模较大的问题是需要求解的子问题都已经求解好了,它的缺点就是可能有些子问题不要算但是它还是算了,而递归实现方式只会计算它需要求解的子问题。
练习1:来试试写写最长公共子序列吧。
练习2:算法导论问题 15-4: Planning a company party 计划一个公司聚会
Start example Professor Stewart is consulting for the president of a corporation that is planning a company party. The company has a hierarchical structure; that is, the supervisor relation forms a tree rooted at the president. The personnel office has ranked each employee with a conviviality rating, which is a real number. In order to make the party fun for all attendees, the president does not want both an employee and his or her immediate supervisor to attend.
Professor Stewart is given the tree that describes the structure of the corporation, using the left-child, right-sibling representation described in Section 10.4. Each node of the tree holds, in addition to the pointers, the name of an employee and that employee’s conviviality ranking. Describe an algorithm to make up a guest list that maximizes the sum of the conviviality ratings of the guests. Analyze the running time of your algorithm.
原问题可以转换成:假设有一棵树,用左孩子右兄弟的表示方式表示,树的每个结点有个值,选了某个结点,就不能选择它的父结点,求整棵树选的节点值最大是多少。
假设如下:
dp[i][0]表示不选i结点时,i子树的最大价值
dp[i][1]表示选i结点时,i子树的最大价值
列出状态方程
dp[i][0] = sum(max(dp[u][0], dp[u][1])) $\quad$ (如果不选i结点,u为结点i的儿子)
dp[i][1] = sum(dp[u][0]) + val[i] $\quad$ (如果选i结点,val[i]表示i结点的价值)
最后就是求max(dp[root][0], dp[root][1])